
Codeforces Round #591 Div2 F / Div1 D. Stack Exterminable Arrays
D. Stack Exterminable Arrays
別解が面白かった。
問題
特殊なstackがあり、以下の一点だけ通常のstackと異なる。
- topと現在挿入し要素している数字が同じとき、その2つの数字は削除される
長さ$n$の自然数列$a$が与えられるので、このstackに順に入れると空になるような連続部分列の個数を求めよ。 ($n \le 3 \cdot 10^5, a_i \le n$)
解法1
Editorialの方針。
言葉で説明するよりも図のほうがわかりやすい気がしたので図を載せておきます。
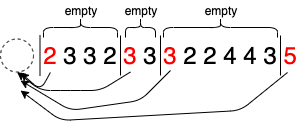
空になる区間ごとにまとめて考えれば良くて、左から愚直にたどっていくと最悪ケースで$\mathcal{O}(n^2)$かかりますが、以下のようにhashmapとcountの累積を考えると$\mathcal{O}(n)$になります。 $$\mathrm{nxt}[i][x]: \{x, a[i], a[i + 1], …, a[r]\}が空になるような最小のr$$ $$\mathrm{cnt}[i]: \{a[i], a[i + 1], …, a[r]\}が空になるようなrの個数$$
実装
いくつかに枝分かれしているような遷移について、mapのその時点の先頭までの累積を計算したいだけだったらmoveを使うと効率的にできる。
#include <bits/stdc++.h>
using namespace std;
using Int = long long;
void solve() {
Int n; cin >> n;
vector<Int> a(n);
for (Int i = 0; i < n; i++) cin >> a[i];
vector<Int> cnt(n + 1);
vector<map<Int, Int>> nxt(n + 1);
Int ans = 0;
for (Int i = n - 1; i >= 0; i--) {
if (nxt[i + 1].count(a[i])) {
Int r = nxt[i + 1][a[i]];
cnt[i] = cnt[r] + 1;
ans += cnt[i];
nxt[i] = move(nxt[r]);
}
nxt[i][a[i]] = i + 1;
}
cout << ans << "\n";
}
signed main() {
cin.tie(nullptr);
ios::sync_with_stdio(false);
Int T; cin >> T;
while (T--) solve();
}
解法2
AtCoderのZero-Sum Rangesと同じ言い換えをします。 具体的には、 $$「空になるような連続区間の個数」=「先頭からみたときのstackの状態が一致するような要素のペアの個数」$$ という言い換えができます(便宜的に先頭に空文字列の要素を追加したものを考えています)。 簡単な証明は末尾に記載していますが、直感的に成り立ちそうなのはわかると思います。
すると、先頭から見たときのstackの状態は文字列として表せるので、Rolling Hashでhash化して個数をカウントしていけば良いことがわかります。
実装
#include <bits/stdc++.h>
using namespace std;
using Int = long long;
using ull = unsigned long long;
template <class T>
struct RollingHash {
vector<ull> hash, pows;
ull base, mod;
RollingHash(const T &a, ull base, ull mod = 1000000009)
: hash(a.size() + 1), pows(a.size() + 1, 1), mod(mod), base(base) {
for (int i = 0; i < a.size(); i++) {
pows[i + 1] = pows[i] * base % mod;
hash[i + 1] = hash[i] * base % mod + a[i];
if (hash[i + 1] >= mod) hash[i + 1] -= mod;
}
}
// 現在の文字列のサイズ
int size() { return hash.size() - 1; }
// [l, r)
ull get(int l, int r) {
assert(l <= r);
ull ret = hash[r] + mod - hash[l] * pows[r - l] % mod;
if (ret >= mod) ret -= mod;
return ret;
}
void concat(const T &b) {
int n = hash.size() - 1, m = b.size();
pows.resize(n + m + 1);
hash.resize(n + m + 1);
for (int i = 0; i < m; i++) {
pows[n + i + 1] = pows[n + i] * base % mod;
hash[n + i + 1] = hash[n + i] * base % mod + b[i];
if (hash[n + i + 1] >= mod) hash[n + i + 1] -= mod;
}
}
void pop_back() {
hash.pop_back();
pows.pop_back();
}
};
constexpr int HASH_NUM = 4;
struct bases_t {
int use[HASH_NUM];
int &operator[](int i) { return use[i]; }
bases_t() {
mt19937 rnd(chrono::steady_clock::now().time_since_epoch().count());
for (int i = 0; i < HASH_NUM; i++) use[i] = rnd() % 10000;
}
} bases;
using multihash_t = array<int, HASH_NUM>;
template <class T = vector<int>>
struct MultiRollingHash {
vector<RollingHash<T>> rhs;
MultiRollingHash(const T &a) {
for (int i = 0; i < HASH_NUM; i++) {
rhs.push_back(RollingHash<T>(a, bases[i]));
}
}
multihash_t get(int l, int r) {
multihash_t ret;
for (int i = 0; i < HASH_NUM; i++) ret[i] = rhs[i].get(l, r);
return ret;
}
int size() { return rhs[0].size(); }
void concat(const T &b) {
for (auto &rh : rhs) rh.concat(b);
}
void pop_back() {
for (auto &rh : rhs) rh.pop_back();
}
};
void solve() {
Int n; cin >> n;
vector<Int> st;
MultiRollingHash<vector<Int>> rh({});
map<multihash_t, Int> mp;
mp[rh.get(0, 0)] = 1;
Int ans = 0;
for (Int i = 0; i < n; i++) {
int x; cin >> x;
if (st.size() && st.back() == x) {
rh.pop_back();
st.pop_back();
} else {
st.push_back(x);
rh.concat({x});
}
multihash_t hash = rh.get(0, rh.size());
ans += mp[hash];
mp[hash]++;
}
cout << ans << endl;
}
signed main() {
cin.tie(nullptr);
ios::sync_with_stdio(false);
Int T; cin >> T;
while (T--) solve();
}
一般化
モノイドの要素列$a$に対して、累積の列
$$ c_i = a_0 a_1 \cdots a_i $$
を考えます。 また便宜上$c_{-1} = e$とします($e$は単位元とする)。
このとき、 $$ a_i a_{i + 1} \cdots a_j = e \Leftrightarrow c_{i - 1} = c_j $$ が成り立つ条件を考えます。
$\Rightarrow$は明らかに成り立ち、$\Leftarrow$が成り立つ条件はモノイドが(左)簡約可能($ab=ac$ならば$b=c$)なことです。
このことから、一般的に簡約可能なモノイド列に対して $$「合成が単位元になるような連続区間の個数」=「(単位元+)先頭からの累積の列について、一致する要素のペアの個数」$$ が成り立つことがわかりました。
簡約律が成り立つ代表的なモノイドとして群があり(左から$a^{-1}$をかければよい)、(整数, 加算)からなる群を考えているZero-Sum Rangesでも成り立つことがわかると思います。
今回の問題設定では、
- 与えられた文字列に対して、連続する同じ文字2つを選んで消去することを繰り返す
という操作はどこからやっても同じ結果になることが帰納法などによって証明できることから、2つの文字列をconcatしたあとにその操作を行うことを考えてもモノイドになっていることがわかります。
簡約律は明らかに成立することから、今回の問題設定でも成立することがわかりました。