
Optunaを使ってAtCoder Heuristic Contest 007を優勝する
この記事は、Optuna Advent Calendar 2021の25日目のものとして書かれました。
はじめに
AtCoder Heuristic Contest (AHC)は、Atcoderが主催するプログラミングコンテストです。 従来のアルゴリズム型のコンテストは問題に対する最適解を求めるのに対して、ヒューリスティック型のコンテストでは最適解を求めるのが難しい問題に対してできるだけよい近似解を求めるものです。 ヒューリスティックなアルゴリズムを設計する際にはハイパーパラメータがしばしば出現するため、今回はそのパラメータをOptunaで調整するという記事です。 なお、AHCでOptunaを使う先行研究はたくさんあるのでそちらも参照するといいかもしれません。
- AtCoder Heuristic Contest 001
- AtCoder Heuristic Contest 003で5位(2.921T点)を取りました
- ヒューリスティックコンのパラメータチューニングをGCPでやる
など
TL;DR
AHC007はオンラインで辺の重みが決まっていく状況で、コストが小さい全域木を求める問題でした。 各ステップでモンテカルロサンプリングを行うという解法が有力だったのですが、その際の辺の重みの生成を実際のデータの分布 $[d, 3d]$ ではなく謎の $[1.13d, 2.87d]$ からの一様分布で生成するとスコアが大きく上がるということが話題になりました(該当ツイート)。
このマジックナンバーが謎だったのでOptunaで探索を行ったところ、 $[1.14094d, 3.01629d]$ がsuggestされました。
これを使うと、1位のスコアを大きく上回りコンテスト後を含めてもadmin以外の全ての提出より良いスコアが得られました(提出)。
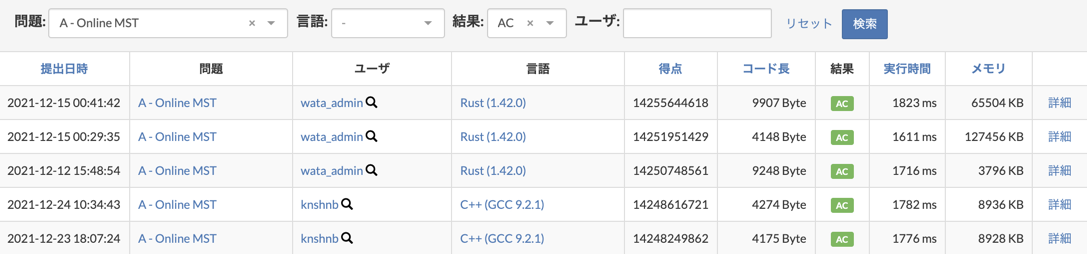
Optuna部分
提出コードはC++、コンテストで与えられたスコア計算ツールはRust、OptunaはPythonのツールですが案外簡単に連携できました。 C++からはコマンドライン引数経由でパラメータを受け取ることにしました。
signed main(int argc, char* argv[]) {
double l_ratio = 1.0, r_ratio = 3.0;
if (argc == 3) l_ratio = atof(argv[1]), r_ratio = atof(argv[2]);
// ...
Pythonからはシェル経由でC++、Rustを実行してパースすることにしました(C++でスコア計算も簡単にできますがRust呼び出しも特にボトルネックにならなそうだったので)。
500テストケースを、Pythonのjoblibを使って各プロセスで os.popen で48プロセス並列でC++を実行しています。
このへんオーバーヘッドがある気もするのでもっといい書き方があるかもしれません。
Optunaでは適当に一様乱数の範囲の左端・右端の係数をそれぞれ1.0周辺・3.0周辺で探索しています。
import statistics
import os
import joblib
import time
import optuna
n_parallel = 48
n_files = 500
def calc_score_each(seed: int, l_ratio: float, r_ratio: float):
in_file = f"in/{seed:04}.txt"
os.makedirs("tools/out", exist_ok=True)
out_file = f"out/{seed:04}.txt"
os.system(f"./hoge {l_ratio} {r_ratio} < tools/{in_file} > tools/{out_file}")
cmd = f"cd tools && cargo run --release --bin vis {in_file} {out_file} 2> /dev/null"
out = os.popen(cmd)
return int(out.read().split()[-1]) / 1e8
def calc_scores(l_ratio: float, r_ratio: float):
scores = joblib.Parallel(n_jobs=n_parallel)(
joblib.delayed(calc_score_each)(i, l_ratio, r_ratio) for i in range(n_files)
)
return scores
def objective(trial: optuna.trial.Trial):
start = time.time()
l_ratio = trial.suggest_float("l_ratio", 0.6, 1.4)
r_ratio = trial.suggest_float("r_ratio", 2.6, 3.4)
scores = calc_scores(l_ratio, r_ratio)
print(f"elapsed: {time.time() - start}")
return statistics.mean(scores)
if __name__ == "__main__":
os.system("g++ -O2 -std=c++17 main.cpp -o hoge")
study = optuna.create_study(
direction="maximize",
storage="sqlite:///ahc007.db",
study_name="tune_range",
load_if_exists=True,
)
study.optimize(objective, n_trials=10000)
Optunaは可視化機能が整備されていて便利でした。
Jupyterで study = optuna.load_study(storage="sqlite:///ahc007.db", study_name="tune_range") などとして optuna.visualization.plot_optimization_history(study) とすると、最適化の様子が可視化されます。
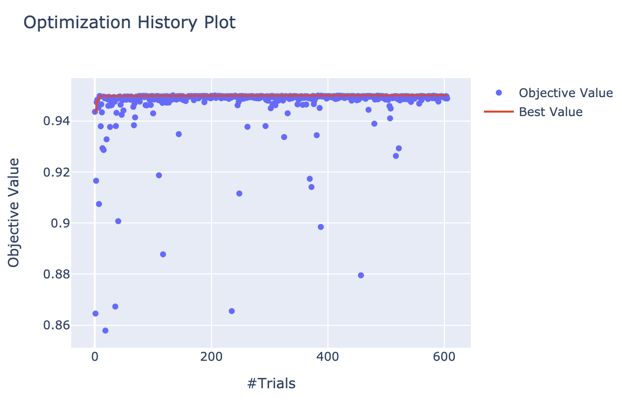
今回は4時間弱回して600 Trialぐらい行きましたが、かなり早い段階で収束していることがわかります。
実際、最適解 (l_ratio: 1.14094, r_ratio: 3.01629) も134 Trial目で得られたものでした。
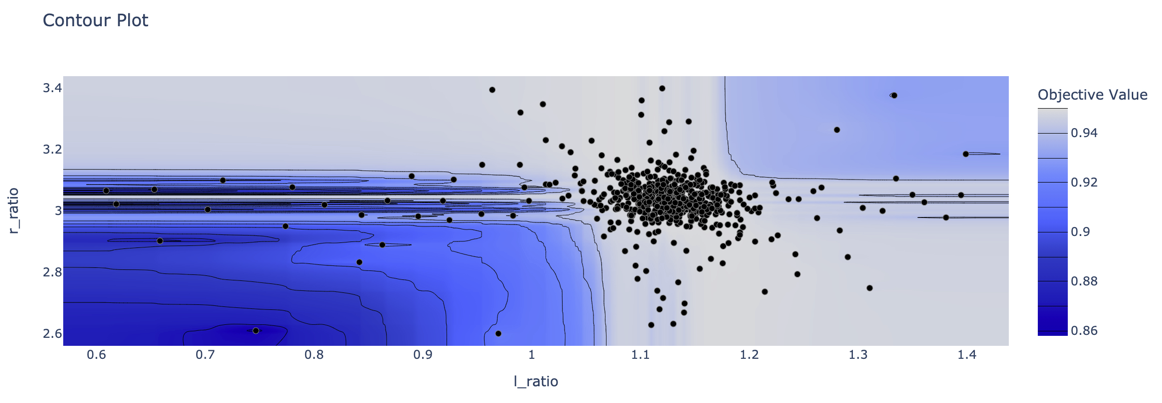
optuna.visualization.plot_contour(study) も雰囲気がわかって面白いです。
グリッドサーチよりもかなり効率的に探索できていそうな様子が伺えます。
詳細説明
(気が向いたらもうちょっと書くかもしれません。)
コンテスト中は、各ステップでモンテカルロサンプリングを無限回繰り返せば最適化したい期待値に収束するという誤解をしていました。 実際は、モンテカルロサンプリングでの設定はすべての辺の重みがわかったオフラインの設定であり、本来求めたいオンラインでの問題設定に比べて有利になってしまっていました。 その部分の補正のためにこのような調整を入れるとスコアが良くなるようです。 wataさんのツイートでこのことについて詳しく解説されています。 なぜ $[1.14094d, 3.01629d]$ が良いのかについては、わかりません。。
おまけ
Optunaがパラメータ調整してくれるならもう少し複雑な関数(ステップ数を用いた1次関数など)を使えばスコアがさらに上がるのではと思って試してみたりしたのですが、パラメータが増えたことによるデータセットへの過学習・Trialが増えたことで確率的に上振れを引いたときに過剰評価されてしまうの問題などが発生してしまいなかなか難しかったです。 Optunaは基本的に目的関数を決定的なものだと思って最適化を行っている(ex. 同じ点を複数回評価しない)と思いますが、目的関数の確率的な挙動も内部で考慮してくれるようなSamplerがあったら便利だと思いました。 技術的にもまだ結構難しいのかもしれないですが。。